

Qu’est-ce que l’ETL ? Comprendre son rôle clé dans la valorisation des données
14 mai 2025
14 mai 2025

L’ETL (Extract, Transform, Load) est un processus d’intégration de données permettant de collecter des données issues de sources multiples, de les transformer, puis de les centraliser dans un système cible afin de les rendre exploitables.
Dans un système d’information, les données sont souvent dispersées entre plusieurs applications et formats.
👉 L’ETL permet de structurer ces données pour les rendre cohérentes et utilisables dans une logique d’analyse et de pilotage.
Avant de parler technique, il faut comprendre le problème.
Dans la plupart des organisations, les données sont réparties entre différents outils : ERP, CRM, applications métiers ou fichiers.
Cette dispersion rend leur exploitation complexe :
👉 Le processus ETL permet de résoudre ce problème en structurant les données et en automatisant leur traitement.
Il constitue ainsi un maillon essentiel entre les systèmes opérationnels et les outils d’analyse.
Derrière cet acronyme se cachent trois étapes clés :
Les données peuvent provenir de multiples sources :
👉 L’enjeu ici est de connecter et récupérer ces données sans impacter les systèmes existants.
C’est l’étape la plus stratégique : structurer et fiabiliser
On va :
👉 Cette phase garantit la qualité et la cohérence des données
Les données sont ensuite envoyées vers un système cible :
👉 Elles deviennent alors utilisables pour le reporting, la BI ou le machine learning.

Schéma du processus montrant les étapes d’extraction, transformation et chargement des données.
Dans un système d’information réel, il ne fonctionne jamais isolément.
👉 Il s’inscrit dans un écosystème plus large, composé de plusieurs briques :
– applications métiers (ERP, CRM, outils spécifiques)
– systèmes d’intégration (EAI, API)
– plateformes de stockage (data warehouse, data lake)
Concrètement, les applications produisent des données opérationnelles, souvent hétérogènes et réparties dans différents systèmes.
👉 L’ETL intervient alors pour :
– collecter ces données depuis les différentes sources
– les transformer selon des règles métiers
– les centraliser dans un référentiel unique
Dans cette organisation :
– l’EAI gère les flux entre applications en temps réel
– les API permettent d’exposer et d’échanger des données
– l’ETL structure les données pour les rendre exploitables
👉 L’ETL joue donc un rôle clé dans la chaîne de valorisation de la donnée, en assurant le lien entre les systèmes opérationnels et les outils d’analyse.
Prenons un cas simple. Une entreprise utilise :
👉 Les données sont réparties et incohérentes.
Le processus va :
Résultat : un reporting unifié, fiable et exploitable.
Cette solution est partout… mais souvent invisible.
C’est son usage principal.
Ce mécanisme alimente les outils de reporting en données fiables et structurées.
Il centralise les données de toute l’entreprise dans un référentiel unique.
Il permet, par exemple :
Il facilite les changements d’outils ou de systèmes.
Ce système est donc un composant clé de toute stratégie data.
| Cas | Objectif |
| BI | Reporting |
| Data warehouse | Centralisation |
| Migration | Modernisation |
Son architecture définit la manière dont les flux sont organisés.
On retrouve généralement :
👉 L’objectif est de structurer les flux de données de manière fiable et scalable.
Batch vs temps réel
Les architectures modernes combinent souvent les deux.
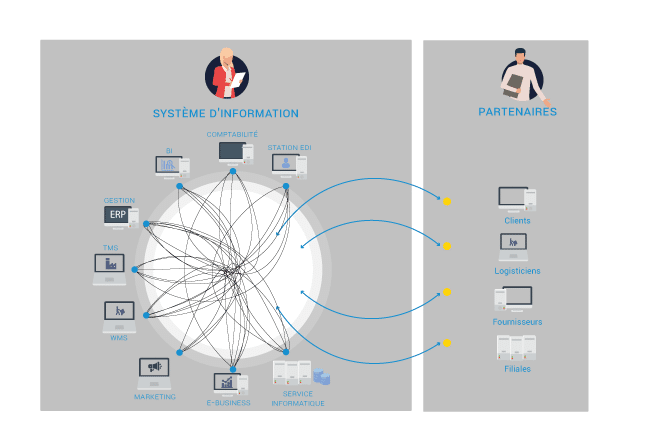
Schéma de l’architecture avec data warehouse et sources multiples
Avec l’évolution des architectures data, de nouvelles approches sont apparues.
Aujourd’hui, ce processus coexiste avec d’autres approches.
| Type | Fonction | Usage |
| ETL | Transforme avant | BI |
| ELT | Transforme après | Cloud |
| Reverse ETL | Redistribue | Opérationnel |
👉Le processus ETL intervient dans la chaîne de valorisation de la donnée, là où l’EAI agit sur les flux opérationnels.
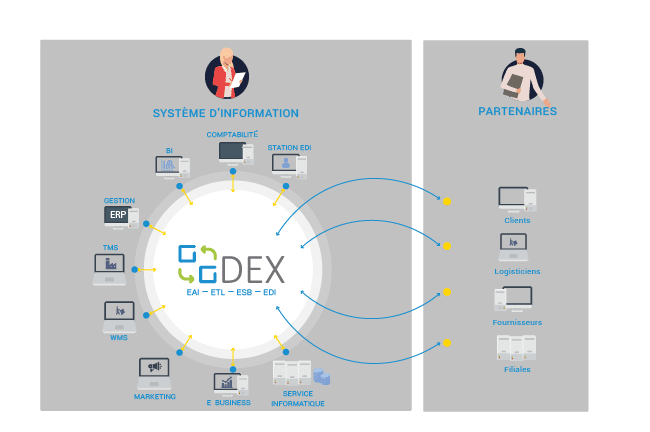
Schéma d’intégration du processus ETL
Mettre en place cette approche ne consiste pas seulement à choisir un outil. C’est avant tout une démarche structurée.
Étapes clés :
👉 L’erreur la plus fréquente est de sous-estimer la complexité des transformations.
La mise en place d’un tel processus peut sembler simple en théorie, mais de nombreux projets rencontrent des difficultés en pratique.
👉 Voici les erreurs les plus fréquentes :
Sous-estimer la complexité des transformations
Les règles de transformation sont souvent plus complexes que prévu, notamment lorsqu’il s’agit de consolider des données issues de plusieurs systèmes.
Négliger la qualité des données
Un ETL ne corrige pas automatiquement les données sources.
Sans contrôle qualité, les erreurs sont simplement déplacées… et amplifiées.
Multiplier les flux sans gouvernance
Avec le temps, les flux peuvent se multiplier et devenir difficiles à maintenir.
Cela entraîne une perte de visibilité et une augmentation des risques.
Ne pas anticiper la volumétrie
Les volumes de données évoluent rapidement.
Une architecture mal dimensionnée peut rapidement devenir un frein aux performances.
Manquer de supervision
Sans outils de suivi et d’alertes, les erreurs passent inaperçues.
Cela impacte directement la fiabilité des analyses.
👉 Pour éviter ces écueils, il est essentiel de structurer les flux dès le départ et de mettre en place une gouvernance adaptée.
Le marché propose aujourd’hui une grande diversité de solutions.
On distingue généralement :
👉 Le choix dépend de la complexité des flux, des volumes et de l’architecture existante.
Un data warehouse ne fonctionne pas sans ETL.
C’est cette méthode qui :
Sans cette solution, il est impossible d’obtenir une vision consolidée et fiable de l’activité.
Malgré ses avantages, ce mécanisme montre certaines limites :
👉 C’est ce qui explique l’émergence de nouvelles approches comme l’ELT, le streaming ou le data pipelines modernes.
La mise en place d’un ETL nécessite une compréhension fine de vos flux de données et de votre architecture.
Nos experts vous accompagnent dans :